
A lot of people, at least in the pre-“vibe coding era,” lament that they can’t program because they’re “not math people.” I wasn’t either. Here’s how I got started building machine learning models in Python anyway.
Why I hesitated
I thought I “wasn’t a math person.”
Despite my interest in technology and computers, math was a struggle, at least in my formal education. While I managed to pass a transferable introductory statistics course at a community college, I got the feeling that advanced math wasn’t for me. Even though I got interested in Linux and dabbled in code, I still felt inadequate mathematically.
Software programs like Mathematica were out of my price range. While there are more open-source alternatives available now, they didn’t seem to exist when I was in school and college, or at least I wasn’t aware of them.
The simplest code that people learn to write just needs basic arithmetic. I would tinker and dabble with code. Still, my encounter with statistics helped me see math as valuable with real applications.
When machine learning became popular, I thought about trying it. I signed up for a free course on Coursera but was quickly lost without the needed background.
But one day, I felt the urge to try to explore statistical programming. I’d explored math articles on Wikipedia from time to time, but there seemed to be a block on getting involved. But once I did, I found it was easy to do. It’s also given me a reason to self-study math, building my own super calculator in Python and teaching myself calculus and linear algebra as well with Schaum’s Outlines.
Setting up my Python environment
Assembling my modeling toolbox
I needed a few tools that are different from the standard Python environment. A lot of statistics, data science, and machine learning in Python is done interactively. It’s best to explore the data and see what it can tell you rather than jump into building a model.

I installed IPython and Jupyter. IPython is an enhanced interactive Python interpreter that adds features like command-line editing and “magic” commands. Jupyter implements interactive notebooks to display results and share them with others. Jupyter notebooks used to be part of IPython, but the developers decided to concentrate on the latter even as IPython is still used in the background as a “kernel.” I use Pixi to install and update these tools.
pandas is a library that manages data in DataFrames. It’s similar to using a spreadsheet or relational database. Seaborn is a library with common statistical visualizations, including bar charts, scatterplots, and regression plots. statsmodels offers classic statistical models like regression. SciPy offers a lot of scientific computing tasks, including common statistical operations.
Exploring the data
You have to know your data to model it
With my environment set up, I now had to explore the data and build a model. First, I had to import my Python libraries:
import numpy as np
import pandas as pd
import seaborn as sns
sns.set_theme()
from scipy import stats
import statsmodels.api as sm
import statsmodels.formula.api as smf
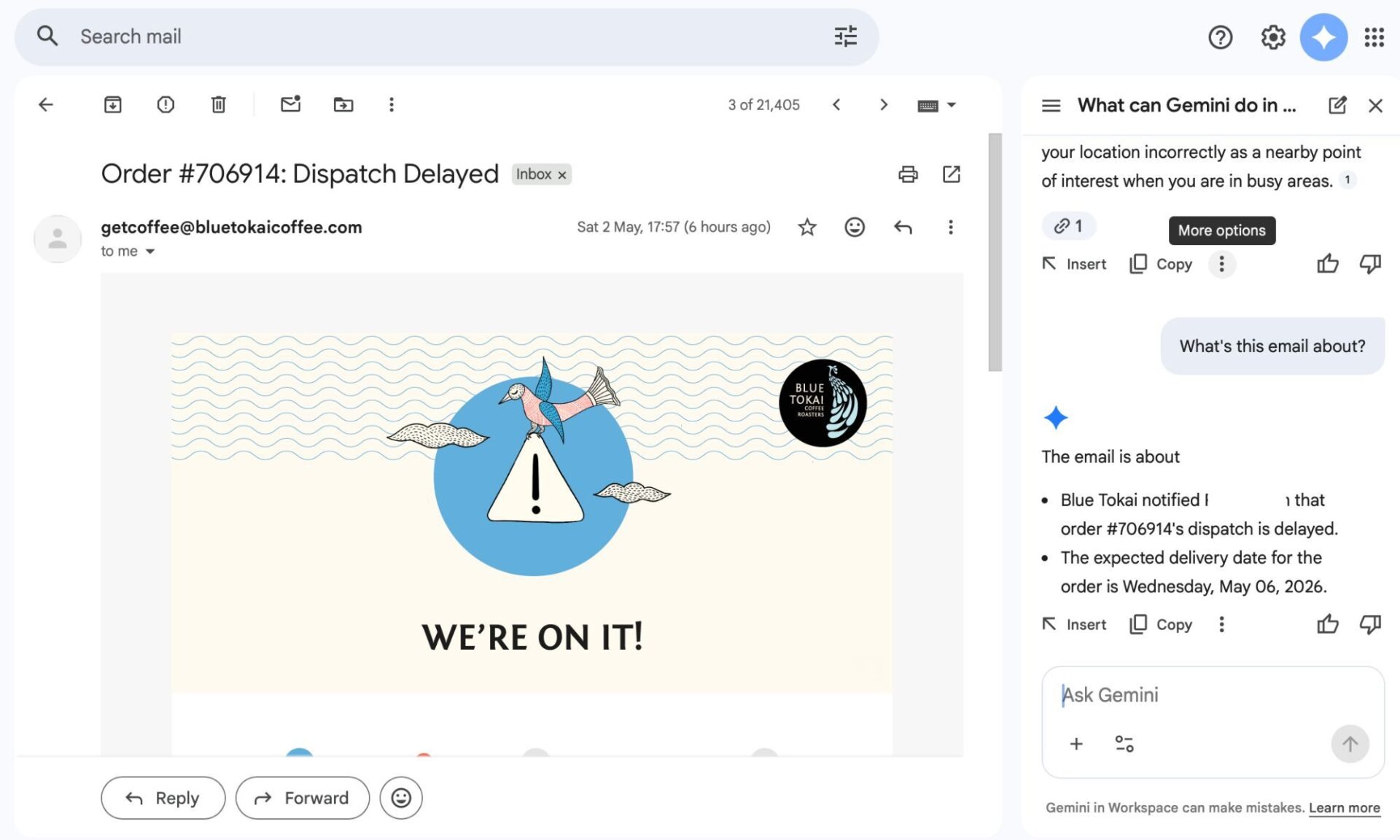
%matplotlib inlineNow I needed some data. Fortunately, Seaborn has some built-in toy datasets. One of them is a dataset from a waiter who tracked the total bill, the tips, the size of the party, and whether there were any smokers in the party in a restaurant over several weekends. Would there be any correlation between the bill and the tip?
First, I’ll load the dataset in using Seaborn:
tips = sns.load_dataset('tips')This loads the dataset in as a pandas DataFrame.
I’ll examine the first few lines:
tips.head()
And take some standard descriptive statstics like mean, median, mode, lower quartile (25th percentile), and the upper quartile (50th percentile):
tips.describe()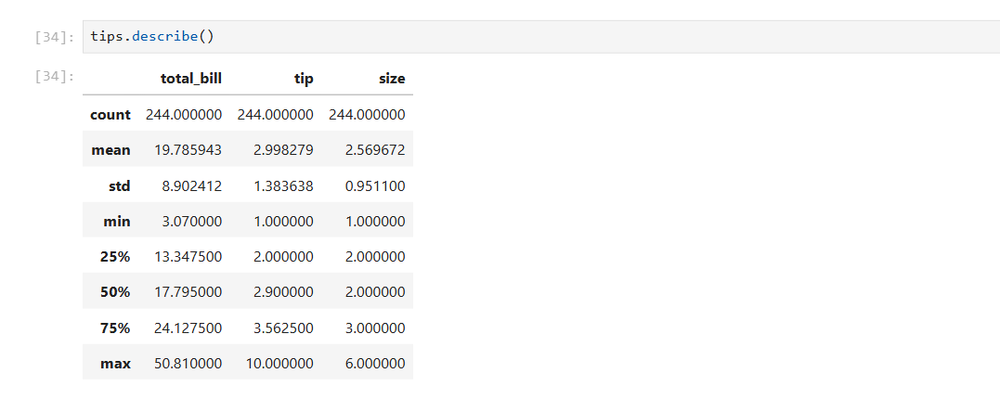
I’ll make a scatterplot with the total bill as the independent variable on the x-axis and the tip as the dependent variable on the y-axis.
sns.relplot(x='total_bill',y='tip',data=tips)
Hmm, there seems to be a positive linear relationship in this scatterplot. I could draw a line over these dots and the tip would rise along with the total bill. Some tips are higher as outliers, but this relationship seems to generally hold.
I can generate a regression plot with such a line drawn over it:
sns.regplot(x='total_bill',y='tip',data=tips)
From exploration to modeling
Python makes it easy to build regression models
Now that I’ve explored my data and found a positive relationship between the bill and the tip, it’s now time to formally model it. This is easy to do with statsmodels:
results = smf.ols('tip ~ total_bill',data=tips).fit()
results.summary()
Briefly, this creates a formula similar to that in R and displays a summary with the model and some diagnostic information. The most useful bit is the left-hand column of the table. This contains the y-intercept and the slope that you might have learned about in an elementary algebra class. This describes the line that was plotted over the scatterplot. If I were a restaurant manager, I would advise the waitstaff to upsell customers, since they’ll get bigger tips and contribute to the restaurant’s bottom line simultaneously.
This is the simple linear regression taught in Stats 101, but it’s really a kind of machine learning. It’s a supervised algorithm, because you’re fitting data to a known target, the y values in the original dataset.
With this model, I can plug values into it and make predictions. But what about new data? That’s where scikit-learn comes in. This is the premier machine learning library on Python. It can split the data into test and training data, and make predictions. I’ll demonstrate, modifying scikit-learn’s tutorial on regression.
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split,LinearRegression
X = tips[['total_bill']]
y = tips['tip']
X_train, X_test, y_train, y_test = train_test_split(X, y)
model = LinearRegression().fit(X_train, y_train)
I can then predict tips from the “test” dataset:
y_pred = model.predict(X_test)I’ll plot the regression lines of the training data vs the test data, again modifying the sckit-learn example:
import matplotlib.pyplot as plt
fig, ax = plt.subplots(ncols=2, figsize=(10, 5), sharex=True, sharey=True)
ax[0].scatter(X_train, y_train, label="Train data points")
ax[0].plot(
X_train,
model.predict(X_train),
linewidth=3,
color="tab:orange",
label="Model predictions",
)
ax[0].set(xlabel="Feature", ylabel="Target", title="Train set")
ax[0].legend()
ax[1].scatter(X_test, y_test, label="Test data points")
ax[1].plot(X_test, y_pred, linewidth=3, color="tab:orange", label="Model predictions")
ax[1].set(xlabel="Feature", ylabel="Target", title="Test set")
ax[1].legend()
fig.suptitle("Linear Regression")
plt.show()
You can see all this code and more on my GitHub account.
Python does the math for me
Python has done the mathematical heavy lifting. This has freed me up to concentrate on things like wondering how valid the model is. And it’s also given me an incentive to study on my own. Modern statistics and machine learning rely heavily on calculus and linear algebra, even though I don’t solve matrix equations or calculate derivatives and integrals directly. I’ve used Python to explore those topics as well, but on my own terms. Armed with Python and my new knowledge, I can explore machine learning even more in the future.

Stephan is the sports journalist for the Maple Grove Report.