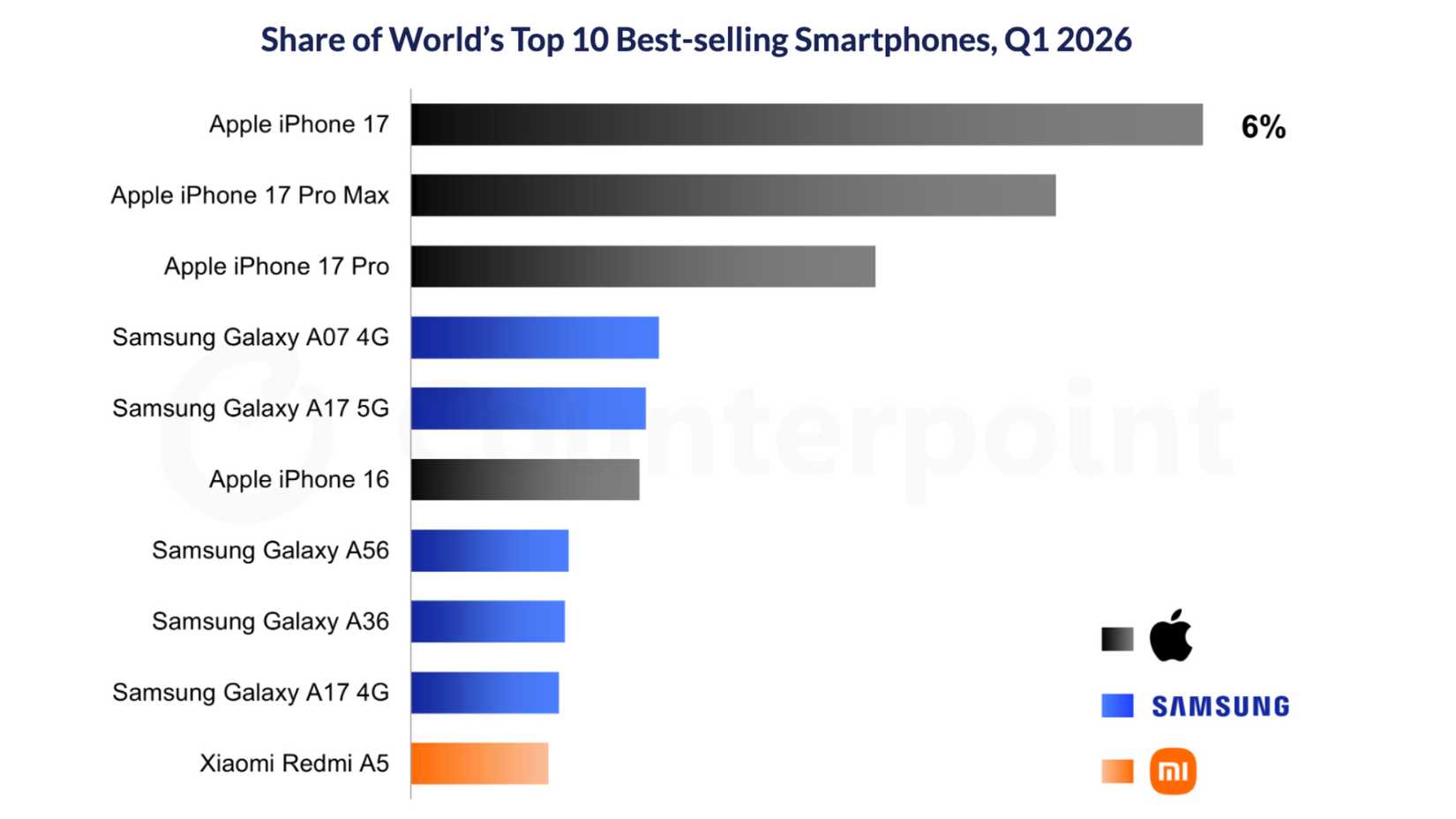

Running your own LLM is surprisingly easy. Using software such as Ollama or LM Studio, you can install and run local AI models that work completely offline. The size and speed of the models will depend on your hardware, but you can run small models even on modest hardware; the real challenge is deciding what to do with your local LLM once you have it up and running.
Working on private documents and data
Keep sensitive data in your own home
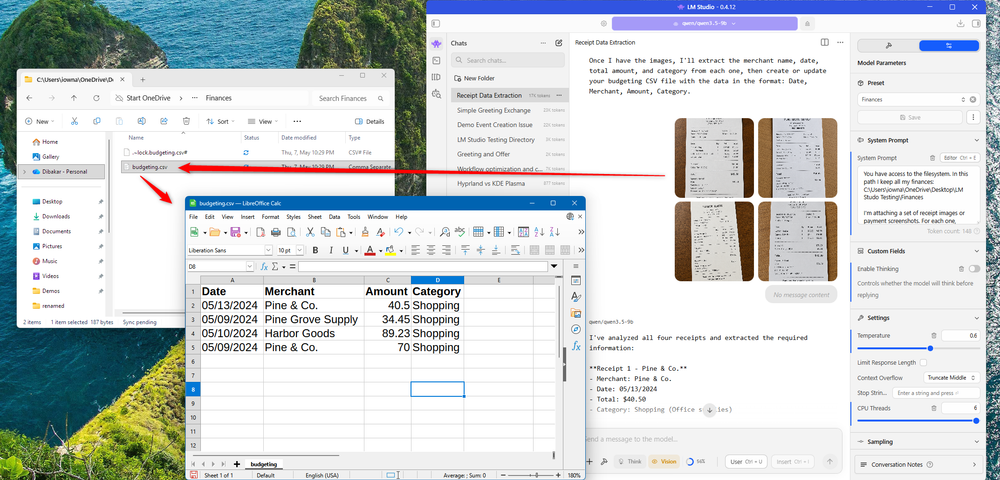
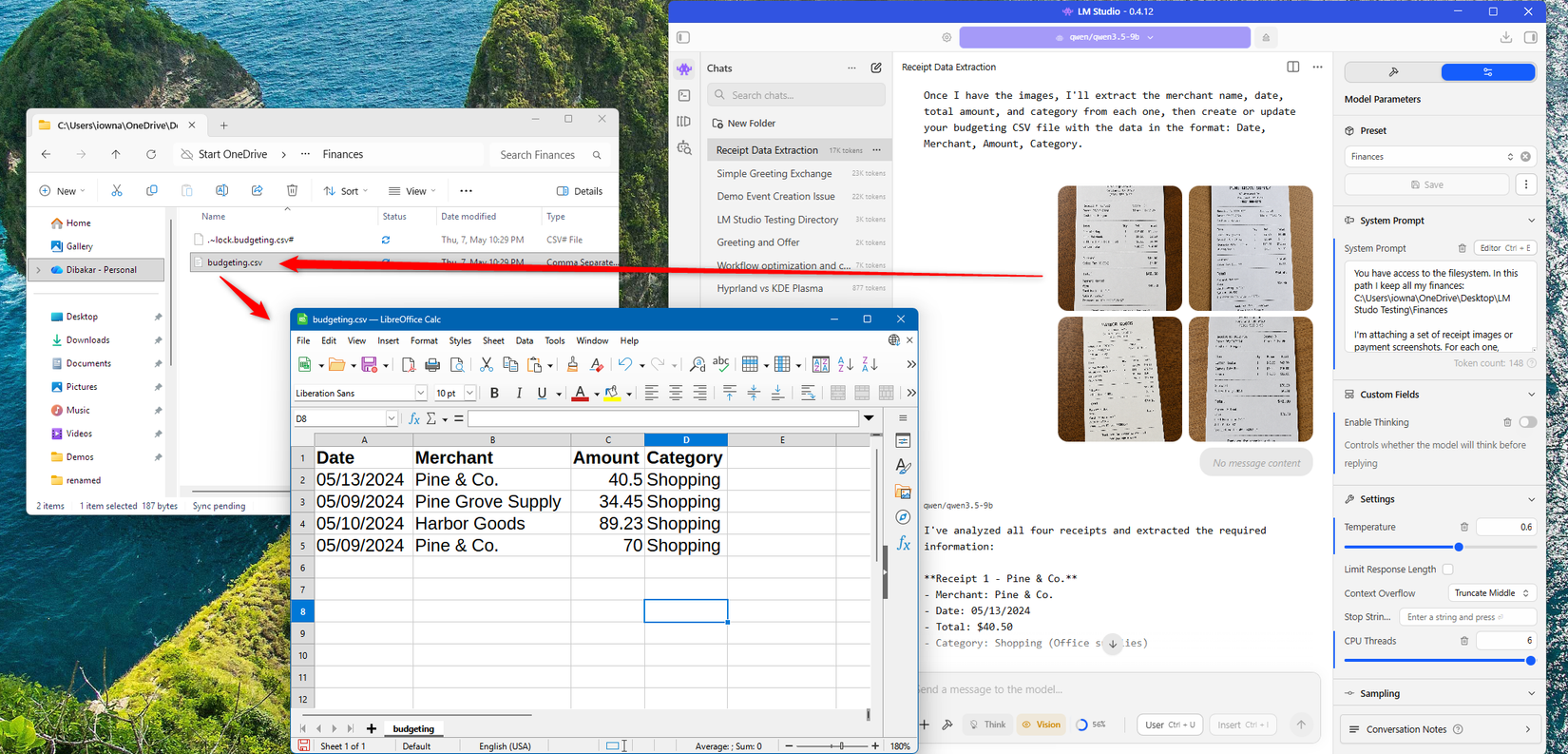
One of the best reasons for using a local LLM is to keep your data private. Everything you type or upload in a cloud-based LLM gets sent to third-party servers where it might be used for training purposes or potentially even read by a human reviewer. This could include sensitive data that you’d rather not share with other people, such as medical or financial information, personally identifiable information, or legal documents.
If there is data you would rather not share, a local LLM is a great way to be able to summarize, analyze, or edit that data without it ever leaving your computer. Even smaller LLMs can be useful for working with text and data, although they’re likely to be slower and less capable. Privacy is one of the key things that a cloud-based AI simply can’t match.
For example, I’ve used a local LLM to strip all the personally identifiable information from a financial tracking spreadsheet before uploading it to a cloud-based LLM to analyze. This way, I get the best of both worlds: privacy and a powerful cloud-based model.
Get help with code instead of having it written for you
Autocomplete and explanations that never leave your machine
AI has made coding accessible to millions of people in a way that wasn’t possible before. You don’t need to know or understand a single line of any programming language to be able to use AI to write usable, working code. The best cloud-based AI models can do incredible things, such as creating an entire working online video game in the style of World of Warcraft.
If you have powerful hardware, you can install large local models that have impressive coding skills, but even if your AI rig didn’t cost the same as your car, you can still use a local LLM to help with coding.
Instead of writing all of your code from scratch, you can use a local LLM as a tool to help you code. You can use one to autocomplete code, explain unfamiliar functions, debug errors, write documentation, or translate code between languages. You can often connect local LLMs to code editors using extensions such as Continue for VS Code.
The response quality and speed will depend on the model you’re running and the hardware it’s running on. It may not be able to create an entire MMO, but it can help make coding easier and keep everything private.
Build a second brain
A local source for your ideas

One issue with a local LLM is that if you want to keep it truly local, it only has access to information on your computer or on the home network. You can give a local LLM access to web search, but then it isn’t operating entirely offline.
An alternative is to build your own local source of data for your LLM. Rather than relying on its training data, you can give your local LLM access to files and documents on your local hardware so that it can answer questions based on that information.
For example, you could give your local LLM access to notes, PDF documents, meeting transcripts, saved web pages, exported emails, and more. Using retrieval-augmented generation (RAG), relevant information from this store of data can be retrieved and supplied to the LLM so that it can answer your prompts using that context.
The quality of responses will often be impacted by the quality and organization of the source documents. Using an organized system of specific documents will work far better than just pointing the LLM at your entire hard drive.
Smart home automation
Keep your smart home local
I use Home Assistant to control and automate my smart home. There are plenty of benefits of using AI with Home Assistant, such as creating your own voice assistant that uses natural language and can understand the intent of commands such as “it’s a bit too dark in the living room.” You can also use a Home Assistant MCP server to let an AI interact with Home Assistant using natural language, allowing it to build automations, create dashboards, or control your smart home, depending on the permissions you grant it.
The problem is that if you use a cloud-based AI service, information about your smart home ends up on third-party servers. This may include sensitive data such as API keys, real-time presence information, your home address, and more.
Using a local LLM is unlikely to give you the same performance as the best cloud-based models, but there is still a lot you can do without having to risk your privacy. I use small local LLMs in many of my automations, including a morning briefing that pulls weather and calendar information, turns it into a written summary, and then converts that summary into speech using a text-to-speech (TTS) engine. This summary then plays through a smart speaker when we enter the kitchen in the morning, and it all works completely locally without any information leaving my home network.
My mini PC doesn’t have a dedicated GPU, so generating the finished briefing takes a while, but this isn’t an issue. I use an n8n automation to generate the briefing early in the morning each day, so it’s ready to play when we come down for breakfast.
Uncensored writing and roleplaying
Escape overzealous guardrails
Another major benefit of running your own local LLM is that you can choose models that don’t have the same restrictive guardrails as most cloud-based LLMs. These chatbots will often flat-out refuse to answer prompts that are asking for medical advice or relate to polarizing topics.
While many of these guardrails are in place for good reason, they can often interfere with legitimate conversations. One example is roleplaying; an AI can be great for text-based roleplaying games, but if you ask to draw your sword to strike down an enemy, it may refuse to continue on safety grounds.
There are uncensored and abliterated models that have some of these guardrails removed or reduced. With a local LLM running one of these models, you may be able to slay that orc after all.
You can do a lot with a local LLM
Unless you’ve spent a small fortune on your setup, a local model is not going to be able to match the performance of the very best closed models running in the cloud. A local LLM can still be very useful, even on modest hardware. You just need to decide how to use it.

Stephan is the sports journalist for the Maple Grove Report.