


If you’ve got a messy Excel spreadsheet with invalid values, blank entries, duplicates, or other problems, you might think you have to spend hours cleaning it up. You can use Python to automate these steps instead. Here’s how.
Setting up a Python environment
Installing the necessary packages

If you don’t already have a Python environment set up, it’s easy to do. If you’re on Windows, I recommend using Windows Subsystem for Linux, or WSL. Python tutorials tend to assume a Linux environment or at least a Unix-like environment, and it’ll be easier to follow along with other tutorials since you won’t have to translate things like pathnames.
If you don’t have WSL installed, you’ll have to do it.
You’ll also want another kind of environment on top of your system. While Python is included in many systems, including almost all major Linux distros, it’s meant more for running scripts and other included software rather than for your own programs. Depending on how quickly an OS updates its software, your version of Python might be older.
You’ll also need to install some libraries on top of Python.
There are several environments that let you install Python packages, but my favorite happens to be Pixi.
In a Linux, macOS, or WSL terminal window, type:
curl -fsSL https://pixi.sh/install.sh | shThis will install Pixi on your machine.
With Pixi installed, you can either create an environment for your packages or you can install them globally. This will probably be the better option for this project, since you’ll have these tools at your fingertips.
The primary package we’ll use is pandas, but we’ll also want some others for this project. NumPy is the foundation for numerical computing with Python. We’ll also want to install Jupyter notebooks. This will give us a graphical way to execute Python code while allowing you to examine it later. IPython is similar, but it works from the terminal.
Let’s install these tools into a global environments
pixi global install numpy pandas jupyter ipython
Getting the data into Python
With our environment installed, we can now start cleaning our messy spreadsheet.
For this example, I’m going to be using a modified version of a dataset I found on Kaggle that’s specifically for learning to clean messy data. It’s got lots of problems, such as missing data, and a lot of “ERROR” or inconsistent terms. It was originally a .csv file, but I saved it out as an Excel file using LibreOffice to demonstrate how pandas can handle Excel files.
I’ll launch Jupyter:
jupyter notebookThis will open up a web browser, or it would if I wasn’t using WSL on Windows. I have to modify the command line to get rid of the error message
jupyter notebook –no-browserI’ll open one of the links in my web browser.
I usually use a shell alias to bypass all of this.
Next, I’ll create a new notebook and use Python as the kernel.
I like to put a header and an explanatory note as Markdown cells.
In the first code cell, I’ll import the libraries I’m going to use
import numpy as np
import pandas as pdNow I’ll read in the messy dataset
cafe = pd.read_excel('/path/to/messy_data.xlsx')I can examine the dataset so you can get a good idea of the problems:
cafe.head()
Dropping missing values
You won’t miss them
The easiest thing to do to clean up a dataset is to remove any missing values. Pandas DataFrames have a built-in method to do that, dropna. Setting the data variable to this method will edit the DataFrame in place:
cafe = cafe.dropna()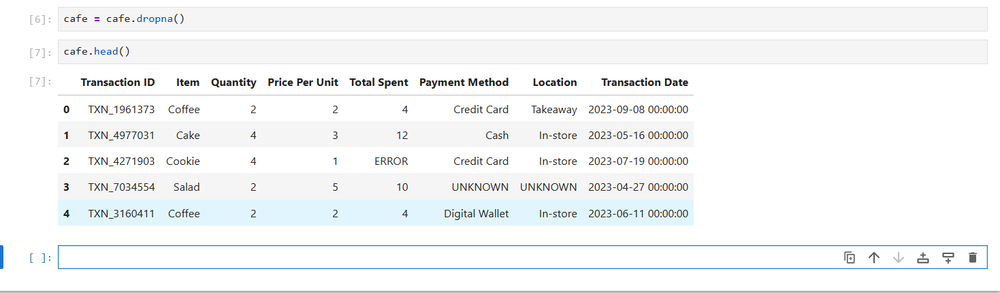
Drop duplicate entries
Don’t double up on data
Now we will want to drop any duplicate entries. Pandas has a built-in method called drop_duplicates that works similarly to dropna:
cafe = cafe.drop_duplicates()
This will again edit our DataFrame in place to get rid of duplicate entries.
Modifying columns
Get rid of invalid values
We still have some problems. A lot of entries in these columns have something like “ERROR” or “UNKNOWN.” We probably won’t want them.
It’s easy to get rid of them. We’ll first create an array of the columns we want to filter:
columns = ['Item','Quantity','Price Per Unit','Total Spent','Payment Method', 'Location', 'Transaction Date']Then we’ll create a for loop that will go through the columns and remove the fields that contain “ERROR” or “UNKNOWN”:
for i in columns:
cafe = cafe[cafe[i] != "ERROR"]
cafe = cafe[cafe[i] != "UNKNOWN"]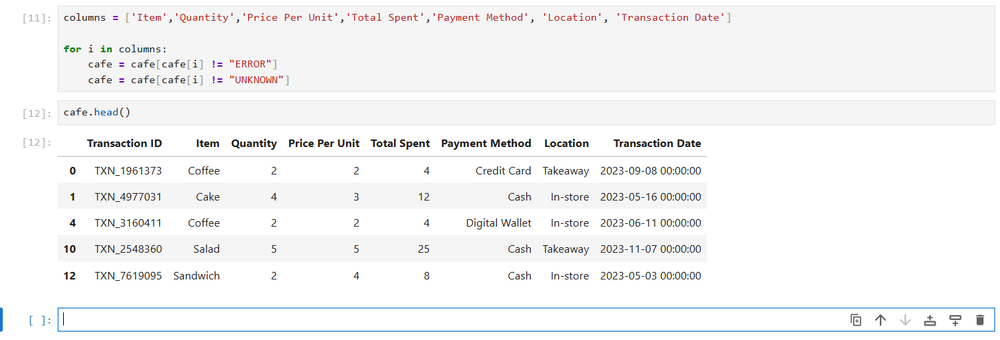
Statements in Python loops must be indented, and Python counts four spaces as indents.
What that loop does is select every value in the column that doesn’t equal “ERROR” or “UNKNOWN” and saves it in place.
Be sure to examine your DataFrame with the head or tail methods to see the effect of your change. If it did something you didn’t want, you can reload in the original data and try again.
This saved a lot of time you would have had to go through all of these in Excel, even running a search and replace operation.
You can run the data.head() command again to see the results.
Putting the data back into the Excel spreadsheet
It’s easy to convert a pandas DataFrame back into Excel
With the data now cleaned, you can save it back to an Excel spreadsheet. You can use the DataFrame’s to_excel method
data.to_excel('/path/to/cleaned_data.xlsx')
It’s easy to clean Excel data in Python
A little time spent learning Python and a bit of pandas can save hours that could be wasted individually editing spreadsheets. Python and spreadsheets like Excel make a good pair: Excel for editing and formatting data, and Python for cleaning and extracting more powerful insights.

- OS
-
Windows, macOS, iPhone, iPad, Android
- Brand
-
Microsoft
- Price
-
$100/year
- Developer(s)
-
Microsoft
- Free trial
-
1 month
Microsoft 365 includes access to Office apps like Word, Excel, and PowerPoint on up to five devices, 1 TB of OneDrive storage, and more.

Stephan is the sports journalist for the Maple Grove Report.




