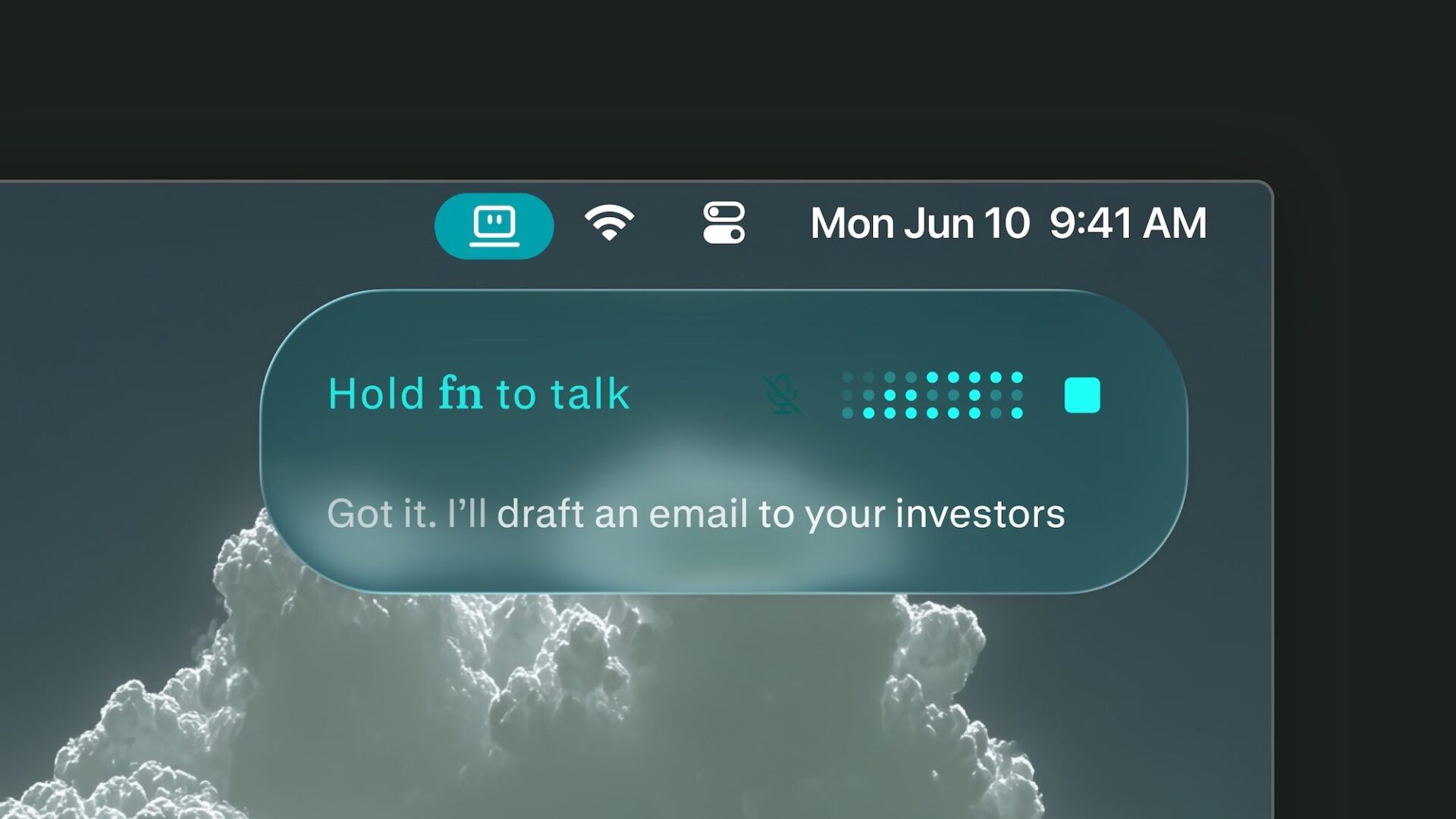
Perplexity has finally launched its Personal Computer Mac app for everyone, and it could genuinely change how you get things done on your Mac.
Personal Computer is an AI agent system that works directly on your Mac. It can dig through your local files, work inside native Mac apps, browse the web, and connect to over 400 tools, all on its own.
You give it a task, and it gets to work. You step in only when it needs your approval. It’s similar to how Claude Cowork works and can handle tasks on your computer.
What can Personal Computer do for you?
If you have ever lost an hour jumping between apps, hunting for a file, or manually pulling information from different sources, Perplexity’s Personal Computer is built for exactly that frustration. It can work across your local files, native Mac apps, connected tools, and the web, all in one go.
Perplexity
Here is a fun example Perplexity showcased. Open Notes, press both CMD keys, and ask it to do your to-do list. It figures out each task and get them done. You can also ask it to clean up a messy folder and sort everything into properly named project folders.
The best part is that you stay in control. It checks in when a decision matters, and every action it takes is reversible. Think of it as a capable assistant, not an unsupervised one.
What’s the best way to run Perplexity Personal Computer?
According to Perplexity, a desktop Mac is the best way to run it, and since the entry cost of a Mac mini is relatively low, it’s the best option. Running Perplexity’s personal computer on a Mac mini is ideal because it can operate continuously, even when you’re away from your desk.
You can kick off a task from your iPhone, and the agents keep working on your Mac back home. You can also approve requests from any device and let it run overnight for complex projects.
Perplexity
That said, the Mac mini is in short supply, so you might have to wait or grab any available model. The new Perplexity Mac app is available today for all users. Everyone gets everyday features like search, attachments, and dictation.
Note that it is not yet on the App Store, so you will need to download it directly from Perplexity’s website.
Trusted quality data is the backbone of agentic AI.
Identifying high-impact workflows to assign to AI agents is key to scaling adoption.
Scaling agentic AI starts with rethinking how work gets done.
Gartner forecasts that worldwide AI spending will total $2.5 trillion in 2026, a 44% year-over-year increase. Spending on AI platforms for data science and machine learning will reach $31 billion, and spending on AI data will reach $3 billion.
The global agentic AI market will reach $8.5 billion by the end of 2026 and nearly $40 billion by 2030, per Deloitte Digital. Organizations are rapidly accelerating their adoption of AI agents, with the current average utilization standing at 12 agents per organization, according to MuleSoft 2026 research. This rate is projected to increase by 67% over the next two years, reaching an average of 20 AI agents.
According to IDC, by 2026, 40% of all Global 2000 job roles will involve working with AI agents, redefining long-held traditional entry, mid, and senior level positions. But the journey will not be smooth. By 2027, companies that do not prioritize high-quality, AI-ready data will struggle to scale generative AI and agentic solutions, resulting in a 15% loss in productivity. While 2025 was the year of pilot experiments and small production deployments of agentic AI, 2026 is shaping up to be the year of scaling agentic AI. And to scale agentic AI, according to IDC’s forecast, companies will need trustworthy, accessible, and quality data.
Scaling agentic AI adoption in business requires a strong data foundation, according to McKinsey research. Businesses can create high-impact workflows by using agents, but to do so, they must modernize their data architecture, improve data quality, and advance their operating models.
McKinsey found that nearly two-thirds of enterprises worldwide have experimented with agents, but fewer than 10% have scaled them to deliver measurable value. The biggest obstacle to scaling agent adoption is poor data — eight in ten companies cite data limitations as a roadblock to scaling agentic AI.
McKinsey identified the top data limitations as primary constraints that companies face when scaling AI, including: operating model and talent constraints, data limitations, ineffective change management, and tech platform limitations.
Data is the backbone of agentic AI
Research shows that agentic AI needs a steady flow of high-quality, trusted data to accurately automate complex business workflows. Successful agentic AI also depends on a data architecture that can support autonomy — executing tasks without human intervention.
Two agentic usage models are emerging: single-agent workflows (one agent using multiple tools) and multi-agent workflows (specialized agents collaborate). In each case, agents will rely on access to high-quality data. Data silos and fragmented data would lead to errors and poor agentic decision-making.
Four steps for preparing your data
McKinsey identified four coordinated steps that connect strategy, technology, and people in order to build strong foundational data capabilities.
Identify high-impact workflows to ‘agentify’. Focus on highly deterministic, repetitive tasks that deliver value as strong candidates for AI agents.
Modernize each layer of the data architecture for agents. The focus on modernization should support interoperability, easy access, and governance across systems. The vast majority of business applications do not share data across platforms. According to MuleSoft research, organizations are rapidly adopting autonomous systems. The average enterprise now manages 957 applications — rising to 1,057 for those furthest along in their agentic AI journey. Only 27% of these applications are currently connected, creating a significant challenge for IT leaders aiming to meet their near-term AI implementation goals.
Ensure that data quality is in place. Businesses must ensure that both structured and unstructured data, as well as agent-generated data, meet consistent standards for accuracy, lineage, and governance. Access to trusted data is a key obstacle. IT teams now spend an average of 36% of their time designing, building, and testing new custom integrations between systems and data. Custom work will not help scale AI adoption. The most significant obstacle to successful AI or AI agent deployment is data quality, cited as the top concern by 25% of organizations. Furthermore, almost all organizations (96%) struggle to use data from across the business for AI initiatives.
Build an operating and governance model for agentic AI. This is about rethinking how work gets done. Human roles will shift from execution to supervision and orchestration of agent-led workflows. In a hybrid work environment, governance will dictate how agents can operate autonomously in a trustworthy, transparent, and scaled manner.
The work assigned to AI agents
McKinsey highlighted the importance of identifying a few critical workflows that would be candidates for AI agents to own. To begin, an end-to-end workflow mapping would help identify opportunities for agentic use. McKinsey found that AI adoption is led by customer service, marketing, knowledge management, and IT. It is important to identify clear metrics that validate impact. Teams should identify the data that can be reused across tasks and workflows.
McKinsey concludes that having access to high-quality data is a strategic differentiator in the agentic AI era. Because agents will generate enormous amounts of data, data quality, lineage, and standardization will be even more important in the agentic enterprise. And as agentic systems scale, governance becomes the primary level for control. The data foundation will be the competitive advantage in the agentic era.
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.