

Whenever I’m at the computer, I seem to have Spotify going in the background. With data on Spotify songs available, I wanted to see if any traits the hit songs had in common. I used Spotify to see if I could build a model of a hit song.
Getting the dataset
Kaggle to the rescue
To examine music data, I would have to find a dataset. As do many other tech companies, Spotify makes data available to developers. I could sign up for a developer account and learn the API to scrape Spotify’s data, but other people have done that for me and posted datasets to Kaggle.
I downloaded one such dataset of over over 30.000 hit songs compiled by Joakim Arvidsson. I used the Kaggle command-line client to download it to my machine:
kaggle datasets download joebeachcapital/30000-spotify-songsI set up a Jupyter notebook to store my analysis, which you can view on my GitHub account.
I then imported my standard Python stats libraries in a cell:
import numpy as np
import pandas as pd
import seaborn as sns
sns.set_theme()
%matplotlib inline
import matplotlib.pyplot as plt
import statsmodels.formula.api as smf
import statsmodels.api as sm
from scipy import statsThis part imports NumPy, a popular numerical analysis and linear algebra library that also includes some common statistics functions. pandas is a library for manipulating tabular data in “DataFrames.” Seaborn is a library for common statistical visualizations. The sns.set_theme() function sets the default theme. The “%matplotlib inline” is a “magic” command that tells Jupyter to render the plots in the Jupyter notebook instead of a separate window. The next line imports the Matplotlib library to create additional plots. The statsmodels lines import both statsmodels and its formula APIs for creating the models I’ll use. Finally, I’ll import the stats routines from the SciPy library into the main Python namespace.
Next, I wanted to import the data into a pandas DataFrame:
spotify = pd.read_csv('data/spotify_songs.csv')
Examining the data
Getting the lay of the land
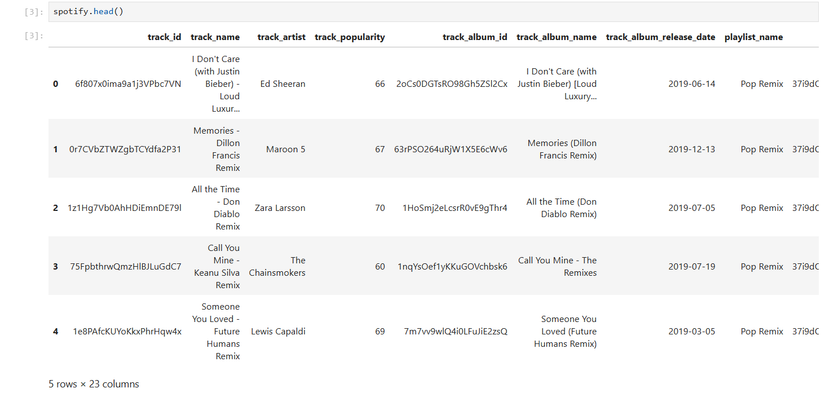
With the data imported, I wanted to explore and visualize it. First, I examined the first few lines of the data to see how it’s laid out:
sns.head()
What do these headings mean? The Kaggle dataset includes a “data card” that explains the columns. Some, such as “track_id,” are unique numbers, while others, like “track_title,” “track_artist,” “playlist_name,” and “playlist_genre,” seem self-explanatory. Others are defined by Spotify. “Acousticness” measures how much acoustic sounds dominate the track, such as acoustic guitars. “Danceability” measures how “danceable” a track is. “Loudness” measures how loud the track sounds. “Instrumentalness” measures how “instrumental” the song is, or how much singing is in it. “Liveness” measures how much the track sounds like a live concert, including audience noise. “Energy” measures how exciting a track sounds. “Speechiness” measures the amount of spoken words in the track. “Valence” measures how “positive” the track sounds.
Now I wanted to see some summary statistics. I used the “describe” method:
spotify.describe()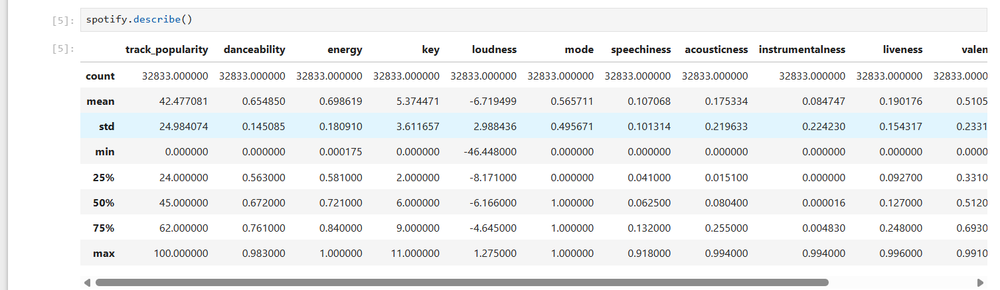
This will calculate some basic descriptive stats, such as the number of elements, mean, the median, the sample standard deviation, the minimum value, the lower quartile or 25th percentile, the median, the upper quartile or 75th percentile, and the maximum of each column. Just by the number of elements, it’s a rather large dataset.
With these numbers calculated, I would then want to look at the distributions. Plotting a histogram of each column can be time-consuming on a dataset with a lot of columns, but I can have pandas plot a histogram for each in one command:
spotify.hist()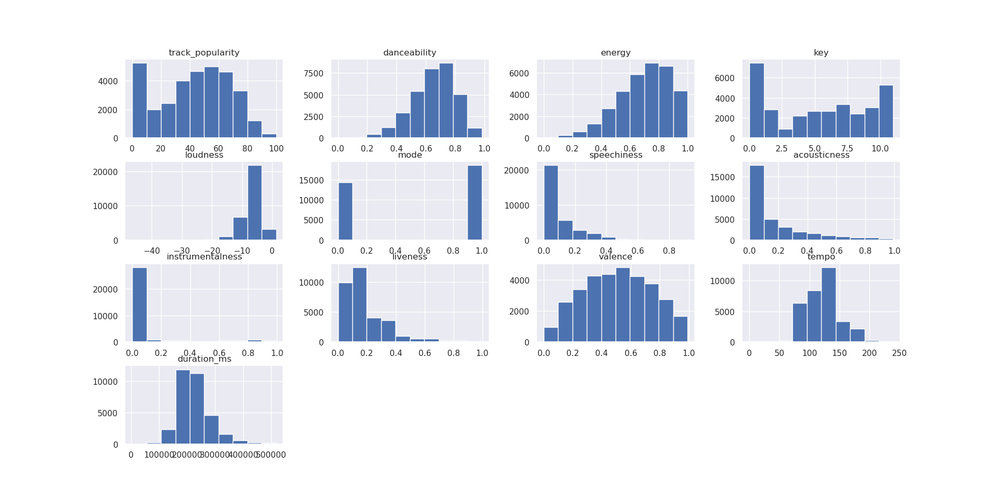
I noticed that a lot of the distributions of the dataset are skewed one way or the other. The track popularity, which I’m trying to predict, has a lot of tracks that don’t seem very popular at all, given by the high bar of 0 on the left of the histogram.
Building a model: track traits
What is a hit song made out of?
With the data loaded in and some visualization done, I wanted to see which variables would have the greatest effect on popularity. My first attempt was to use statsmodels to run an ordinary least squares regression on the other variables. I used the formula method from statsmodels:
results = smf.ols('track_popularity ~ danceability + energy + key + loudness + mode + speechiness + acousticness + instrumentalness + liveness + valence + tempo + duration_ms',data = spotify).fit()
results.summary()The chart showed an attempt to fit a model, but there was a message saying that the numerical results might not be reliable due to possible collinearity, or values lying on the same line.
I decided to try regularized regression, since it penalizes extreme results:
results = smf.ols('track_popularity ~ danceability + energy + key + loudness + mode + speechiness + acousticness + instrumentalness + liveness + valence + tempo + duration_ms',data = spotify).fit_regularized()It doesn’t have the same results method, but there’s a params attribute to see the coefficients. The coefficients can tell you how the effect of a change in one variable affects the result, and whether there’s a positive or negative relationship.
results.paramsHere are the results:
Intercept 57.497818
danceability 6.867472
energy -21.567406
key 0.095799
loudness 1.123025
mode 1.183389
speechiness -5.345878
acousticness 6.543464
instrumentalness -12.618947
liveness -3.144802
valence 4.081272
tempo 0.064768
duration_ms -0.000032
dtype: float64The biggest negative predictors against popularity, based on the coefficients, are energy, speechiness, and instrumentalness. The bigger positive predictors seem to be danceability, loudness, and valence. If your acoustic set killed it at the last open mic, you might try to get a record deal. If you create instrumental music, you probably wouldn’t want to give up your day job soon.
Building a model: genre
The kind of music matters too
I also wanted to see if genre was a predictor of success. For that, I would go to analysis of variance, or ANOVA. First, I made a box plot of popularity by playlist genre:
sns.catplot(x='playlist_genre',y='track_popularity',kind='box',data=spotify)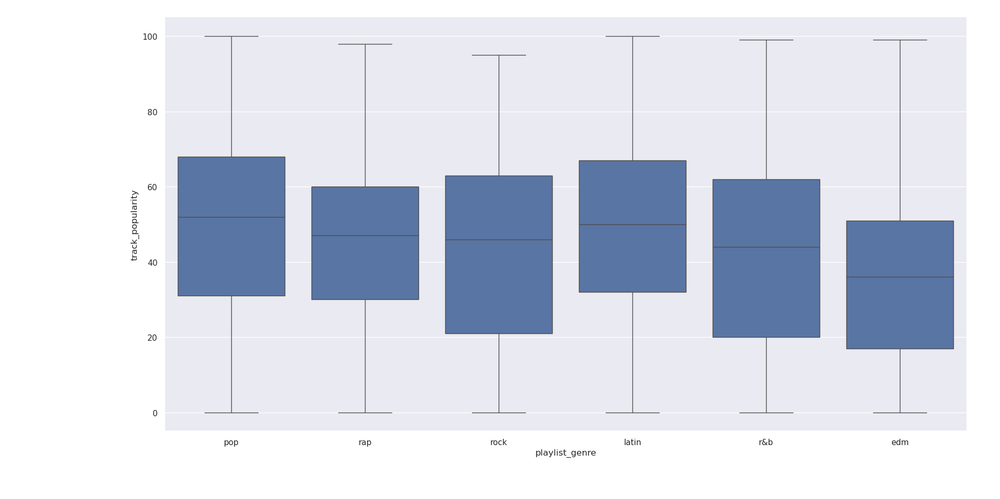
The box plot seems to suggest a significant difference in track popularity among playlist genres. I created another linear model, this time using a category:
Then I used this linear model on the anova_lm method.
sm.stats.anova_lm(genre_lm)
Since the p-value is so low, this means that genre is a significant predictor of popularity. I’ll make a bar plot of track popularity by genre:
sns.catplot(x='playlist_genre',y='track_popularity',kind='bar',data=spotify)
If you wanted to have a hit, you might want to get on Latin and pop playlists.
Maybe you can predict some hits
While music is subjective, perhaps some broad traits can be predicted. Maybe people just like certain musical elements in a certain way. A song in a currently popular genre could be a big hit. But music can’t always be boiled down to numbers. It’s still fun to explore a human experience statistically with code.
- Subscription with ads
-
No ads on any paid plan
- Price
-
Starting at $11.99/month, or $5.99/month for students

Stephan is the sports journalist for the Maple Grove Report.


