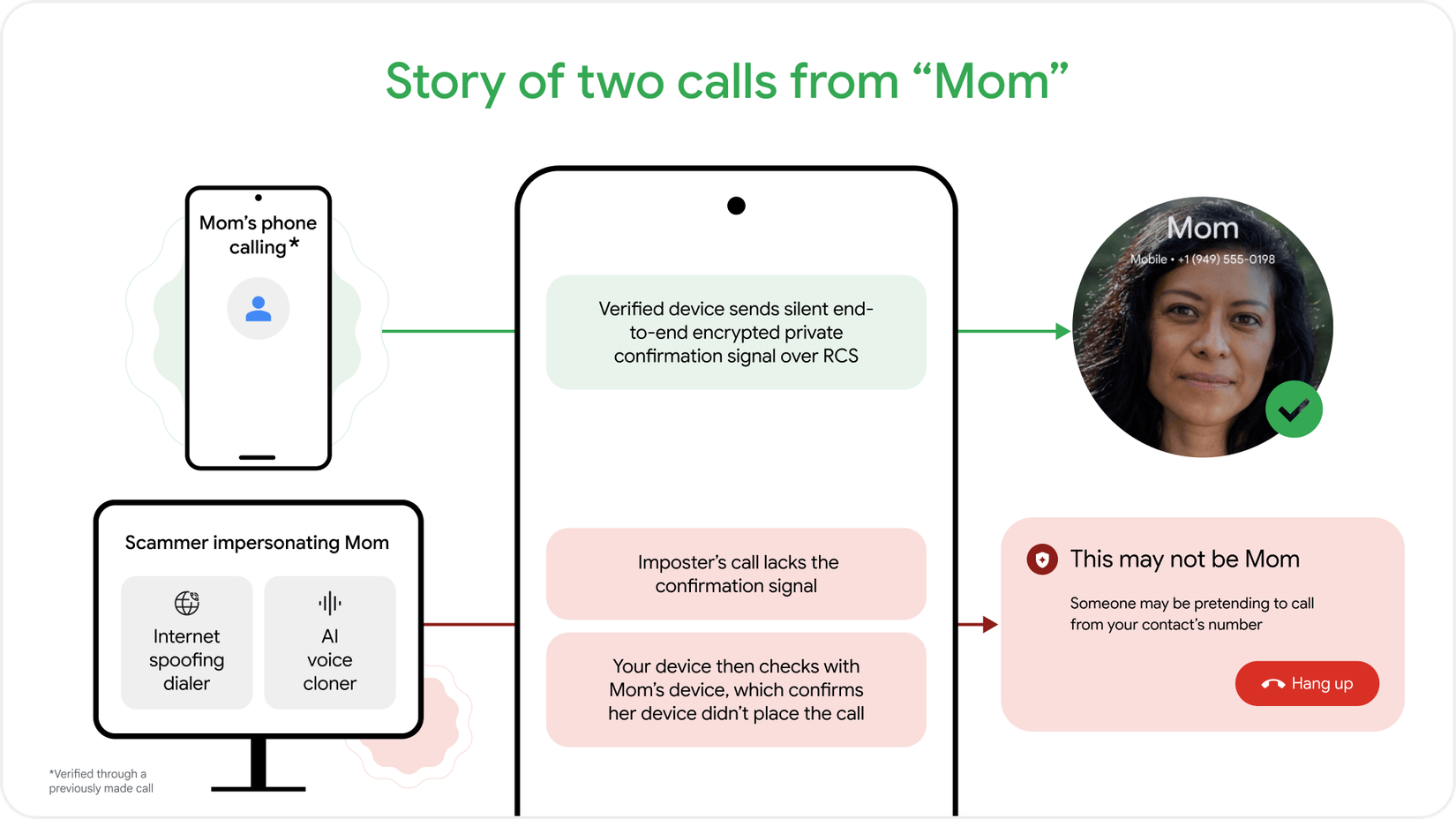

I recently wrote about buying a mini-PC for under $300 and using it to run a local LLM. I expected that process to be interesting, but I also expected it to feel a little rough around the edges. Local AI has always sounded useful in theory, but it also carried a lot of baggage. You had to think about system requirements, model sizes, command-line tools, and whether your computer was actually powerful enough to do anything meaningful.
What surprised me was how approachable it had become. I wasn’t building a server, setting up a developer environment, or turning my PC into some complicated AI workstation. I was installing an app, choosing a model, and actually using a local LLM for normal tasks. That changed how I thought about the whole category. If you have a decent computer and you’re comfortable installing regular desktop software, local AI is no longer something you have to admire from a distance. It’s something you can actually use.
I didn’t even need the command line to install models
Ollama made adding a local LLM feel like installing any other app
The part that really surprised me was how little setup was involved. I went into this expecting at least some amount of command-line work, because that’s usually where local AI starts to lose regular users. On Windows, that meant opening PowerShell, pasting in a command, and hoping I didn’t miss a step. In fact, that’s exactly how I started. I installed Gemma 3 through PowerShell first because I assumed that was just part of the process.
Then I realized Ollama already let me install models right from its own interface. That was the moment this stopped feeling like a developer experiment and started feeling like normal PC software. I wasn’t hunting through documentation, copying commands from a setup guide, or wondering whether I had done something wrong. I could open the app, choose a model, and get started. That’s a big shift. If you know how to install a program and click through a basic app interface, local AI is no longer out of reach.
Choosing the right model mattered more than I expected
My PC could run local AI, but not every model made sense
Installing Ollama was the easy part. Choosing the right model took a little more work. My mini-PC doesn’t have a dedicated GPU, so I couldn’t just grab the biggest model I saw and expect it to run well. That was the part of the process that felt the most complicated, because I had to match the model to the hardware I actually had, not the hardware I wished I had.
That meant doing some research, trying a few options, and paying attention to how each model felt in actual use. Some models were too slow to be practical, while others were better suited to my setup. After testing a few models, I eventually landed on Gemma 3:12B as the one that made the most sense for this mini-PC. That was an important lesson. Local AI is much more approachable than it used to be, but the model still matters. The right one can make the whole experience feel practical, while the wrong one can make local AI feel like a chore.
I also checked Ollama’s reported performance, because “usable” can mean different things depending on the hardware. With Gemma 3:12B running on my mini-PC without a dedicated GPU, Ollama reported a prompt eval rate of 31.78 tokens per second and an eval rate of 7.1 tokens per second. In plain English, it could process my prompt reasonably quickly, but it generated the response at a much more modest pace. That was still usable for outlines, summaries, notes, and basic writing help, but it didn’t feel as fast as using a cloud-based chatbot.
I used it for real work, not just AI demos
Ollama became useful once I gave it ordinary PC tasks

Once I had the right model running, I stopped thinking about Ollama as something I was testing and started using it like another tool on my PC. That was the real shift. It wasn’t just there so I could ask it trick questions or see whether a cheap mini-PC could technically run AI. I started using it for the kinds of small, everyday tasks where I normally might open ChatGPT without thinking too much about it.
That included things like working through rough ideas, cleaning up notes, summarizing text, comparing options, and helping me think through basic outlines before I turned them into something more polished. It wasn’t always as fast or as polished as a cloud-based chatbot, but it didn’t need to be. For a lot of low-stakes, practical work, it was good enough to be useful. More importantly, it was running locally, so I didn’t have to think as much about whether every half-formed idea, private note, or early draft really needed to leave my computer.
Cloud chatbots still have the upper hand in some places
Local AI is useful, but it doesn’t replace everything

Ollama changed how I think about local AI, but it didn’t make me abandon ChatGPT, Claude, or Gemini. Cloud-based chatbots are still better when I need faster responses, current information, stronger reasoning, or features beyond basic text. That doesn’t make local AI less useful. It just gives it a different job. Ollama doesn’t need to beat the biggest cloud models at everything. It just needs to be good enough for the everyday tasks where privacy, control, and convenience matter more.
-

- What’s included?
-
Unlimited conversations, faster response speed, priority access, and more
- Brand
-
ChatGPT
ChatGPT’s AI-supported assistance gets even better with a paid subscription; it Plus tier offers enhanced features including unlimited conversations, faster response speed, priority access, and more.
Ollama made local AI feel ready for regular PC users
Ollama didn’t make local AI perfect, and I didn’t expect it to. Some models are still faster than others, and choosing the right model for your hardware still takes some research. Ollama also isn’t the only app trying to make local AI easier. LM Studio is another popular option, especially if you want a more traditional desktop-style interface.
But Ollama was the one that made the process click for me. It turned local AI into something that felt approachable on a regular PC. I could install an app, choose a model, and start using it for real tasks without turning the whole thing into a weekend project. For anyone who’s been curious about local AI but assumed it was too technical, that’s the real breakthrough. Ollama made it feel like local LLMs are finally moving out of the developer corner and onto everyday computers.

Stephan is the sports journalist for the Maple Grove Report.