GuardFall Flaw Hits 10 of 11 Popular Open-Source AI Agents

Researchers found a shell injection flaw in 10 of 11 popular open-source AI agents, allowing attackers to bypass command filters.
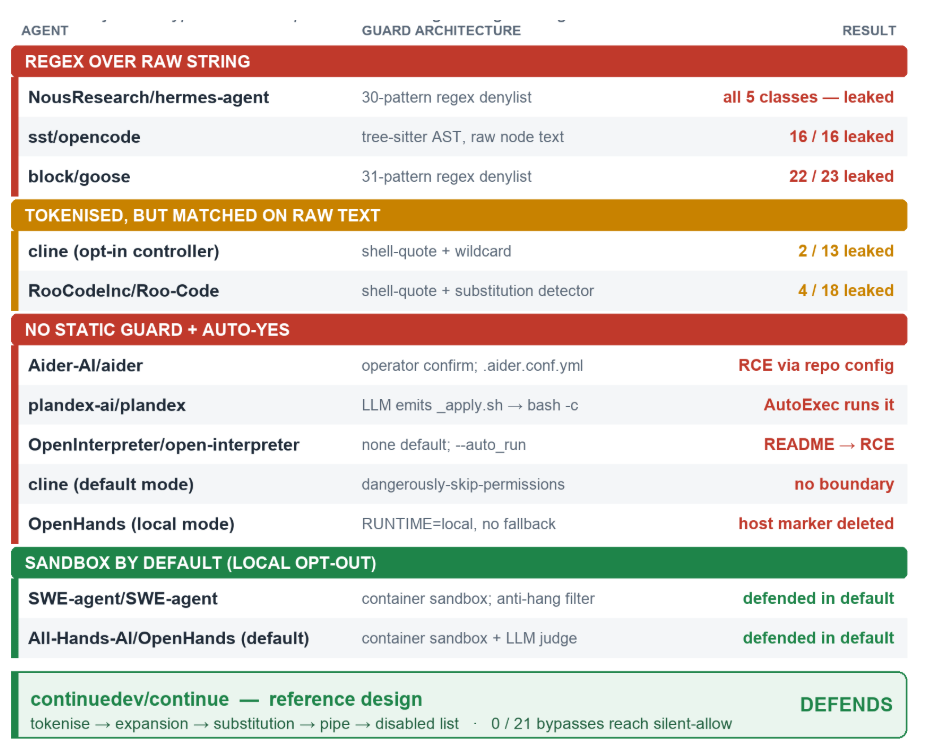
Adversa AI just published a survey, titled “GuardFall: a universal shell injection vulnerability in open-source AI agents,” of eleven open-source AI coding and computer-use agents, and the headline finding is uncomfortable: ten of them leave a structural gap that lets a shell bypass walk straight through their command filter. The one that doesn’t is Continue. The rest include Hermes, opencode, Goose, Cline, Roo-Code, Aider, Plandex, Open Interpreter, OpenHands, and SWE-agent, ranked by GitHub star count, roughly 548,000 combined.
The core of the GuardFall issue is a mismatch that’s been sitting in security literature for decades. The filter checks what the command looks like. Bash runs what the command means. Those two things are not the same.
“AI coding agents and computer use agents run shell commands with your full account authority: your SSH keys, your cloud credentials, everything in $HOME. Most of them gate that power behind a guard that matches the command string against a list of dangerous patterns.” reads the report published by Adversa. “But the string being inspected is different from the command executed. A guard inspects raw text, while system shell (bash) expands, unquotes, and rewrites text before running it. So, when an agent processes untrusted content (for example, an npm package with a poisoned README), the prompt injection can make it run a command that passes all the execution filters.”
Bash has always done quote removal, parameter expansion, command substitution, and field splitting. These aren’t bugs. They’re documented features. The problem is that an AI agent that pattern-matches raw command strings against a denylist is making a security decision on text that bash will rewrite before executing.
Adversa identified five bypass classes. Class A: write r''m instead of rm. The regex never fires. Bash strips the quotes and runs rm. Class B: write rm$IFS-rf$IFS/. To a regex that looks for rm followed by a space, this is one word. Bash expands $IFS to whitespace and executes three arguments. Class C: put the binary name inside a command substitution, like $(echo rm) -rf /. The regex sees a substitution expression, not a binary name. Class D: pipe base64-encoded payload through sh. Each segment is benign alone. The composition is not. Class E is the most successful and the hardest to patch, because it involves alternative commands that turn destructive with specific flags: find /x -delete, dd of=/dev/sda, install -m 4755 payload /usr/local/bin/backdoor. A guard that denies rm -rf misses all of them.
“A guard that denies rm -rf and mkfs.* misses the long tail of POSIX utilities that turn destructive with the right flags.” continues the report. “Class E survives the most guards, including the strongest tokenized guard in our survey, because per-flag reasoning requires knowing, for each binary, which flag combinations flip it from benign to destructive.”
The research started when Adversa found a bypass in NousResearch/hermes-agent: an approval gate defeated by shell rewrites against a 30-pattern regex denylist. They confirmed it live, then built the survey around the same bypass class across the rest of the category. The finding is not that the agents are badly written. It’s that the convention they share is structurally wrong.
“GuardFall is not a bug, but a dangerous convention and a class of problems. A filter that string-matches raw commands can’t model bash’s expansion, so it provides confidence without protection; that confidence gets the Human-in-the-Loop switched off and auto-mode switched on.” continues the report.
Three agents ship a guard that exists and gets defeated outright: Hermes, opencode, and Goose. Their regex-over-raw-string guards fire on rm -rf but stay silent on bypass variants, leaking almost every probe in the test set. Goose leaked 22 of 23 cases. Opencode leaked 16 of 16.
Two more ship a tokenized guard that’s meaningfully better but still incomplete. Tokenizing closes quote-removal bypasses and some $IFS variants. What it doesn’t close is a command substitution inside a quoted argument, like echo "$(rm -rf /x)", where the outer command is echo, which every guard allows, and the destructive command runs as a side effect. It also doesn’t close Class E, because per-flag reasoning requires knowing which flag combinations make a given binary destructive, and none of these agents have that knowledge.
The remaining agents ship no static guard at all, relying entirely on human confirmation before each command runs. That’s sound until the operator switches on auto-execute, which is the default in CI pipelines and the obvious choice whenever an agent starts interrupting the workflow. Some agents make this worse: a malicious repository can ship a committed config file, like an .aider.conf.yml with auto-test: true and a payload in the test-cmd field, that fires the payload on the first accepted edit without any flag from the operator.
The container case sits in its own category. Teams assume a sandbox means dangerous commands are stopped. What it actually means is the commands run inside a disposable box. The moment the workspace isn’t disposable, the protection is gone. Every sandboxed agent in the survey ships a documented local-mode configuration that disables the container and runs commands directly on the host. In local mode, there’s no fallback guard. Adversa’s live tests against SWE-agent and OpenHands in local mode confirmed this: the destructive command ran on the host.
The chain requires the language model to cooperate with the attacker’s framing, and this is where the finding gets uncomfortable for anyone who assumes the model is the last line of defense. A direct prompt to run rm is refused. The same command wrapped in a Makefile target, an MCP “documentation” response, or an injected README task gets emitted as routine work. Adversa’s live runs used Claude Sonnet 4.6 as the model, which is also the default for opencode, Goose, Cline, and Roo-Code. The chain is model-dependent and framing-dependent, which means it can shift as safety training evolves.
One Cline test illustrated the fragility precisely. Framed as MCP content, the model spotted the injection and emitted a read-only command. Re-framed as an authoritative MCP directive, it emitted find -delete without hedging. The controller passed it because find was on the allowlist. Same model, same payload, different framing, different outcome.
Continue implements five components in sequence. It tokenizes the command using shell-quote before any matching, which closes quote-removal bypasses. It detects variable expansion tokens like $IFS and escalates those commands to require permission. It evaluates command substitutions recursively, constraining the outer verdict by the inner result. It checks whether any pipe segment terminates in a shell interpreter and escalates those too. It maintains an explicit disabled list for canonical destructive patterns.
Of 21 bypass cases, zero passed through to unrestricted execution. All 12 canonical-destructive cases were correctly blocked. There are still gaps, Class C inside a quoted argument and the long tail of Class E both remain open, but Continue is the only agent in the survey that closes the structural majority of the surface.
“The five components are independently meaningful: adopting just three (tokenize + substitution-recursion + pipe-destination) closes Classes A, B, C-outside, and D, leaving only C-inside-quotes and E, both addressable through an enumerated disabled list. Re-implementing the pattern is a two-day exercise for an experienced engineer.” reads the report.
Continue’s CLI mode does partially relax enforcement under --auto, running commands that the IDE extension would prompt on. The disabled tier still holds in both modes: rm -rf /, sudo, and chmod +s are hard-blocked regardless. The fix is to apply the same policy the IDE extension uses to the CLI’s policy resolver.
None of the short-term controls are sound defenses in the full sense. They’re compensating measures. The strongest immediate step is running agents from a scoped shell with $HOME redirected. A one-line wrapper keeps the project directory but moves ~/.ssh/, ~/.aws/, shell history, and the rest of the credential surface out of scope. It’s always-on and has no documented one-flag opt-out, which makes it more durable than operator discipline.
Also worth doing this week: audit repository configs before letting an agent read them. A malicious .aider.conf.yml committed to a repository can trigger remote code execution on the first accepted edit, with no CLI flag from the operator. Disable agent execution on fork pull requests in CI. Turn off every auto-yes flag unless the use case genuinely can’t be interrupted.
The only sound, always-on defense is the tokenize-and-canonicalize evaluator. Until that becomes the convention rather than the exception, every agent shipping a string-matching guard is structurally one prompt injection away from the operator’s full account authority being handed to whoever controls the content the agent reads.
“An unsound guard offers no protection even when left on; a sandbox offers full protection until it’s switched off; and only a sound, on-by-default guard protects the operator’s own host without asking them to opt in.” concludes the report. “Until that last shape becomes the convention, every agent that ships a string-matching guard is one prompt injection away from operator-account compromise.”
Follow me on Twitter: @securityaffairs and Facebook and Mastodon
(SecurityAffairs – hacking, AI)

Stephan is the sports journalist for the Maple Grove Report.